



Every startup needs data to build a better product. This isn't up for debate. But, as we've found from working with hundreds of startups at all stages, the "startup data stack" can quickly devolve into a mess of tools slowing you down.
In this article, I'll explain how and why the startup data stack begins like this...
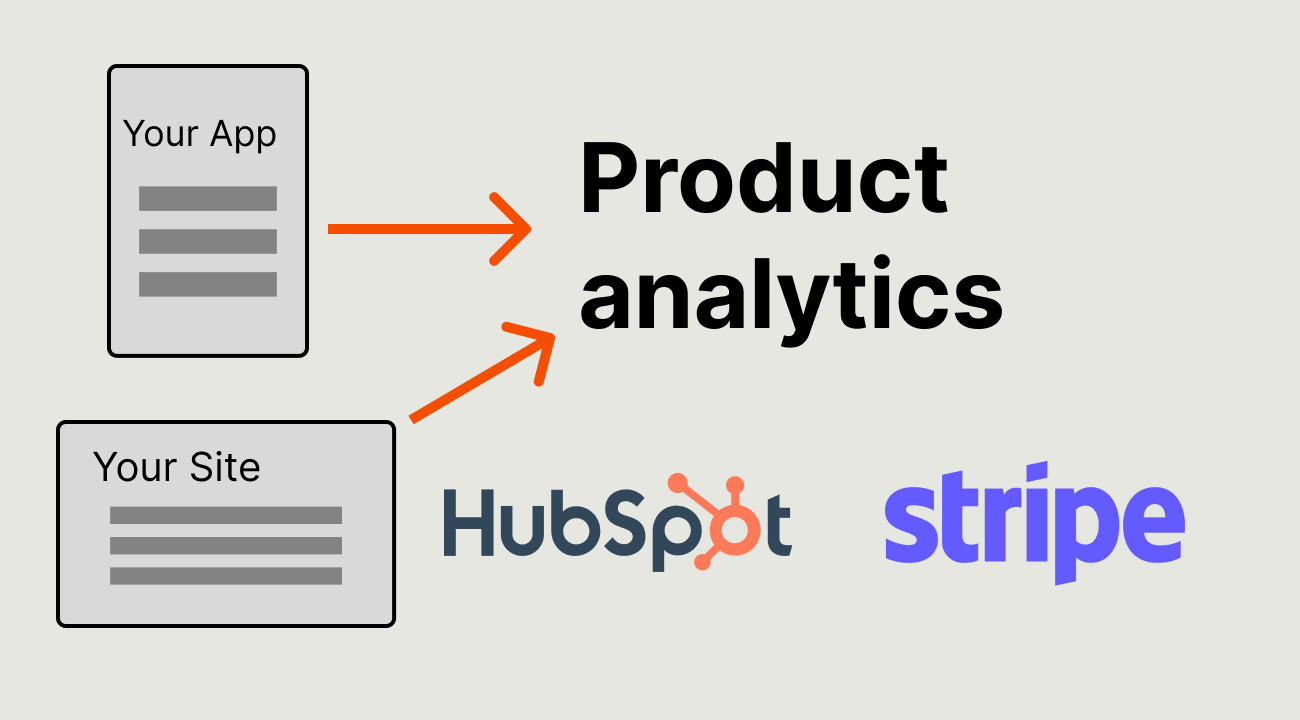
devolves into this...

...and what we're building at PostHog to make this mess less painful for growing startups.
The MVP data stack
When a product is forming, data needs and collection is straightforward. A typical pre-product-market fit startup doesn't need many tools. We call this the MVP data stack.
The goal of the MVP data stack is to get a signal that what you are building is working. Teams need quick and easy tools that give them data for:
- Site visitors
- Leads, signups
- Product usage
- Revenue
To do this, they use:
- Website and/or product analytics
- A customer relationship manager (CRM)
- Revenue, payments, subscription tracking
At this stage, startups usually go with the most popular tools because they are boring technologies that work for others. Complicated solutions aren’t needed, and teams can spend their time building.
The Seed stage data stack
Your data needs start to spiral once you reach Seed stage – as does the complexity and number of tools you need. Why? Because it's less obvious how to spend your time and resources. Typical questions at this stage include:
- What features should we prioritize developing?
- How do we best serve our ideal customer?
- How do we optimize our conversion funnel?
- What channels should we be advertising on?
To answer these questions, you need to pull data from a growing number of sources - product analytics, CRM, help desk, ad platform, payment processors, and more. You also begin to utilize more of the features of these sources, such as customer engagement and session recordings, generating even more data.
This is where customer data platforms (CDPs) like Segment or RudderStack come in. CDPs make it easier to bring data together by collecting it from different sources and sending it to various destinations. For example, a CDP might collect product data from PostHog, advertising data from Google, and revenue data from Stripe, and send it back to those same tools or a warehouse for use with a business intelligence tool like Hex.
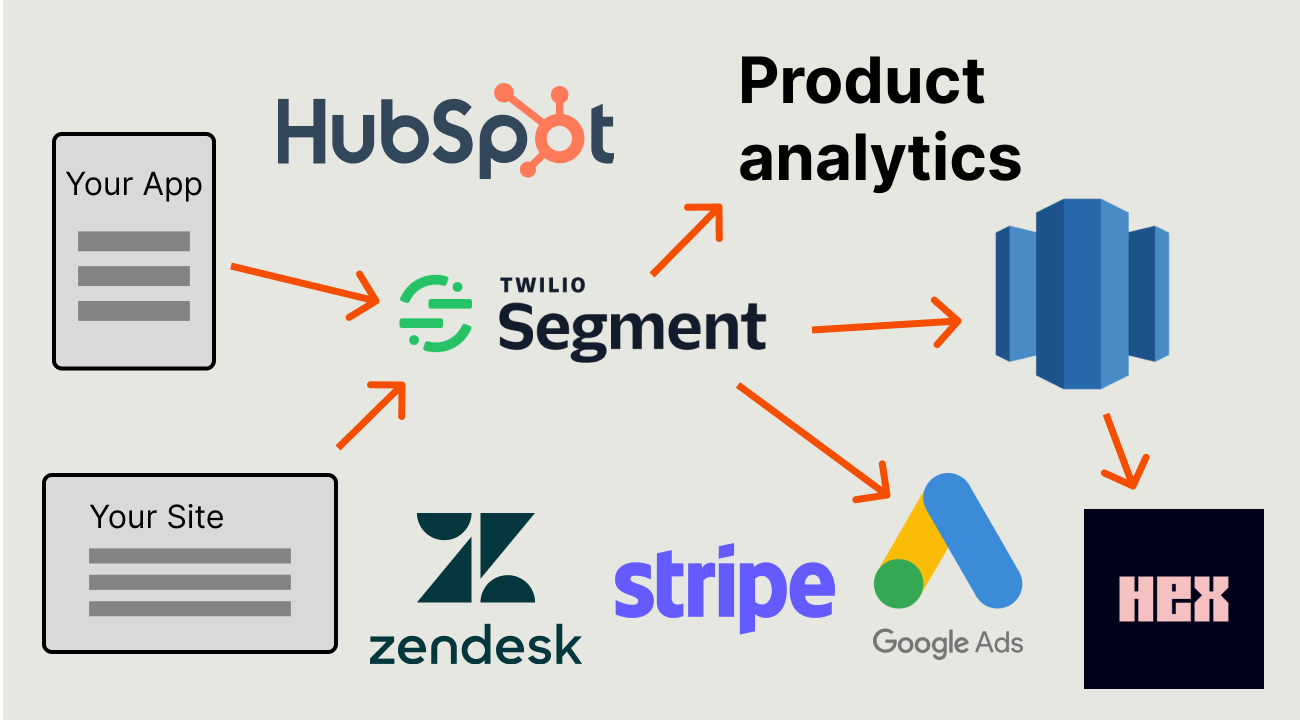
The goal of the stack at this stage is to use data to make better decisions about all aspects of the product. This includes:
- Feature prioritization
- KPI and progress reporting
- Marketing strategy, channel and ad targeting
- Sales forecasting and support
Moving from individual sources to a CDP makes gathering and distributing data faster, but it's also where complexity and maintenance increase rapidly. Data accuracy problems proliferate at this stage, though for now, this isn't a critical issue – engineers just need enough data to know what to prioritize.
The Series A data stack
Series A is where data begins to get serious. By serious, I mean:
- You need someone responsible for the data stack – normally a head of data, data engineer, or a backend engineer
- Accuracy becomes a key objective
Whoever gets the thankless responsibility of maintaining the data stack sees their goal as empowering engineers with data to evaluate the success of what they build. To do this, they implement the so-called "modern data stack" which contains:
A data warehouse to store all the data and act as a single source of truth. Options include Snowflake, BigQuery, and RedShift.
An ETL pipeline to extract data from different sources, transform it, and load it into the warehouse. Options include Fivetran, Integrate.io, and Airbyte.
A data transformation tool to model data, clean it up, and make it usable. dbt is basically the only option.
A business intelligence or visualization tool to get insights from the data you’ve collected. Options include Metabase, Looker, and Hex.
A potential assortment of other tools such as reverse ETL, data orchestration, and data governance.
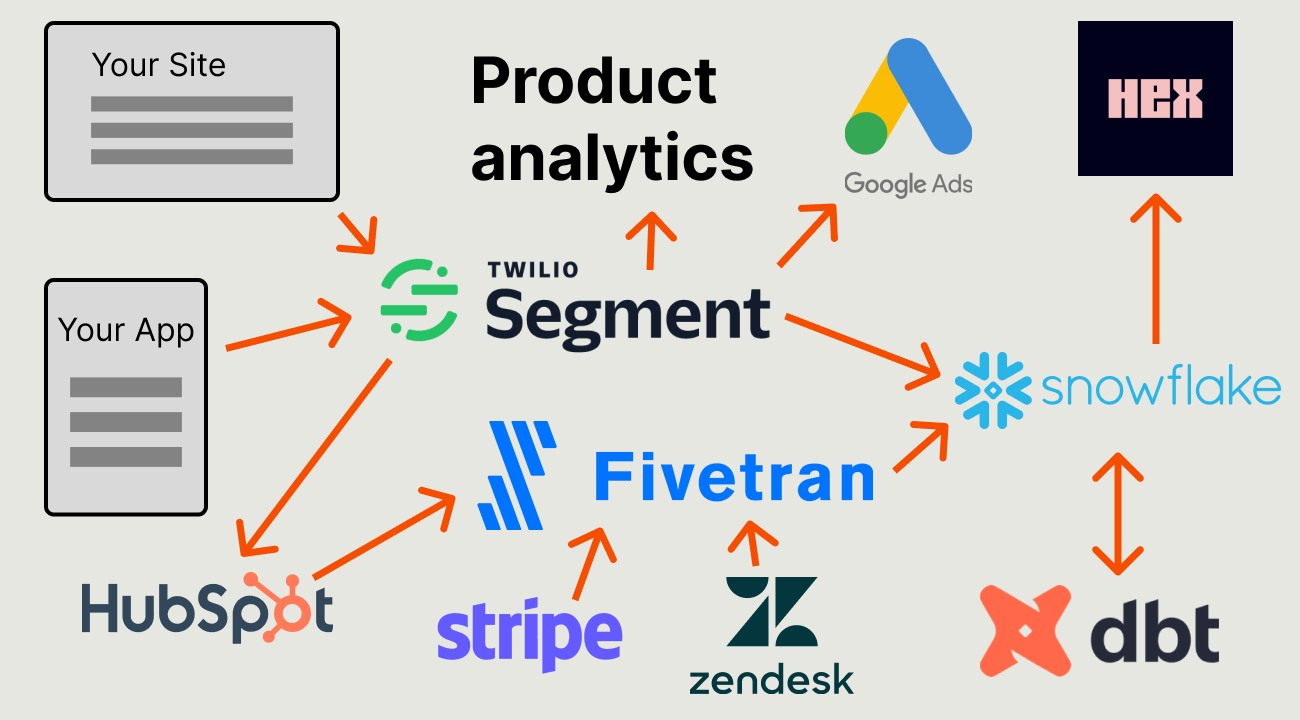
Startups need this stack because managing and accessing individual sources of data becomes unsustainable. Tools like analytics and the CDP don't give complete insight into performance. Teams need a reliable, single source of truth they trust. They hope the modern data stack gives them that.
The problem with the modern data stack is that it often fails the people it was originally meant to serve. It creates a gap between engineers and the data that is valuable to them. They are unable to self-serve and must learn the modern data stack tools, or rely on the data team for insights. There are many reasons for this:
- The complexity of data and tools requires specialization.
- Data security, safety, and privacy requirements.
- Lack of knowledge of data available or how to use it.
For example, engineers might need to write optimized SQL queries to understand customer feature usage. This requires an understanding of SQL, data availability, data structure, as well as access. All this does is slow down their work, blocking them from shipping new features and improvements efficiently.
How we are fixing the modern data stack
If you haven't figured it out already, we're not fans of this situation. To us, the modern data stack creates barriers to building successful products. We want to streamline how startups gather and analyze data at the earliest stages, consolidate more of the stack as they scale, and keep data close to the people who need and use it.
We want to make it easy to evaluate whether products are working or not. Key to this is the ability for engineers to find and analyze the data they want, along with tools like experiments and session recordings. The modern data stack creates complexity and silos that make figuring out what to work on and what’s working unnecessarily difficult.
Improving PostHog as a CDP
To change this, we are improving PostHog as a customer data platform (CDP). We built the key functionality, such as the ability to:
- Receive data from your app(s) and site(s) with our SDKs
- Receive data from sources like Hubspot, Intercom
- Export to destinations such as Snowflake, BigQuery, or RedShift
Improving reliability, integrations, and UX is critical for success here. Being a CDP gives startups access to their data and tools in one place with PostHog. More data also improves the depth of insights engineers can get from PostHog without having to use other tools such as BI or visualization.
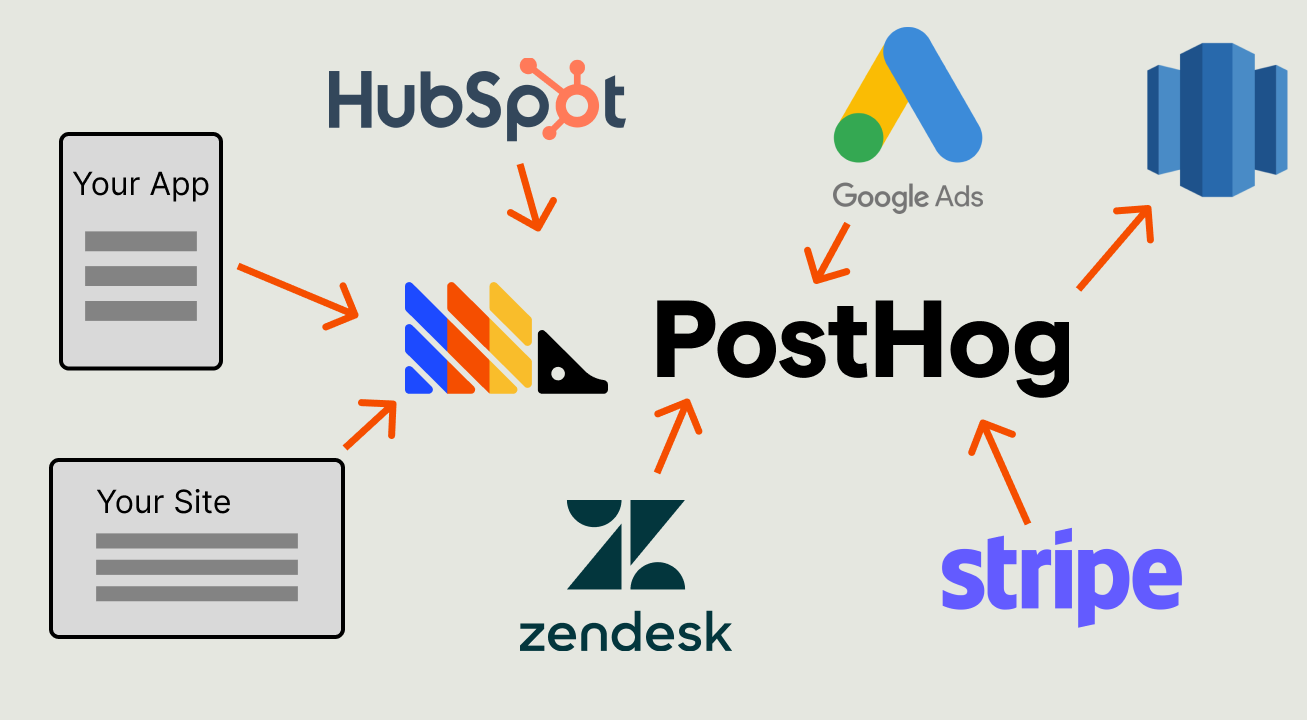
Building a data warehouse
To go one better, we are also working on making PostHog a data warehouse. This means storing and using arbitrary data from many different sources, scaling this up to users needs, and integrating with traditional data warehousing tools. Our team built this at our last Hackathon.
It consists of custom tables that are created and queried through the PostHog UI and API. These tables provide a way to store and query data from sources like Stripe, Hubspot, Intercom, and more along with data from PostHog.
This improves data accuracy and reporting flexibility. It also enables teams to continue using PostHog (which they are familiar with), as they scale. This replaces many of the tools of the modern data stack, which means they don't have to set up or maintain it. They can spend their time and resources building a great product.
Integrating more of the startup data stack into PostHog enables engineers to continue to access the data, insights, and tools for building a great product. The current data stack evolution becomes large, complicated, and siloed quickly. Building an ideal data stack for engineers is what PostHog aims to do, and by doing so, we achieve our goal of more successful products in the world.